件、简历扫描软件和网络搜索算法,它们 数据也充斥着性别数据缺口。
数据也充斥着性别数据缺口。 搜索
搜索 英国国家语料库[34](收录20世纪晚期大量文本中1亿个单词),发现女性代词出现率始终只有男性代词
英国国家语料库[34](收录20世纪晚期大量文本中1亿个单词),发现女性代词出现率始终只有男性代词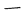 半左右。[35]尽管当代美国英语语料库有5.2亿个词,收录近至2015年文本,但男女代词比例也是2比1。[36]依据这些满是缺口语料库来训练算法,就给人留下这样种印象:这个世界实际上是由男性主宰。
半左右。[35]尽管当代美国英语语料库有5.2亿个词,收录近至2015年文本,但男女代词比例也是2比1。[36]依据这些满是缺口语料库来训练算法,就给人留下这样种印象:这个世界实际上是由男性主宰。
图像数据集看来也存在性别数据缺口问题:2017年,项对两组常用数据集分析发现,男性图像数量远超女性图像;这两组数据集包含“来自网络10万多张复杂场景图像,并附有说明”。[37]华盛顿大学项类似研究发现,在他们所测试45种职业中,女性在谷歌图像搜索中出现比例偏低,其中CEO比例最为悬殊:美国27%CEO是女性,但在谷歌图像搜索结果中,女性只占11%。[38]搜索“作家”结果也是不平衡,谷歌图片中只有25%搜索结果是女性,相比之下,美国作家中女性实际占比有56%,研究还发现,至少在短期内,这种差异确实影响人们对某个领域性别比例看法。当然,对于算法来说,影响会更长远。
这些数据集不仅未能充分代表女性,而且歪曲她们形象。2017年项对常用文本语料库分析发现,女性名字和相关用词(“妇女”“女孩”等)与家庭关系大于与职业关系,而男性情况正好相反。[39]2016年,项基于谷歌新闻流行公共数据集分析发现,与女性相关最热门职业是“家庭主妇”,与男性相关最热门职业是“名家大师”。[40]与性别相关十大职业还包括:哲学家、社交名人、队长、前台接待员、建筑师和保姆——你可以自行猜测,哪些是男性,哪些是女性。2017年图像数据集分析还发现,图像中包含活动和物体表现出“明显”性别偏见。[41]研究人员之马克·亚茨卡尔预见这样种未来:如果机器人是通过这些数据集来训练,当它不确定人们正在厨房里做什 时候,它就会“给个男人杯啤酒,让个女人帮忙洗碗”。[42]
时候,它就会“给个男人杯啤酒,让个女人帮忙洗碗”。[42]
这些文化成见可从现已广泛使用人工智能技术中找到。例如,斯坦福大学教授隆达·席宾格想把报纸对她采访从西班牙语译成英语,而谷歌翻译和Systran翻译系统都反复使用男
请关闭浏览器阅读模式后查看本章节,否则可能部分章节内容会丢失。
